Since the inception of R10k there has been a recipe of 1 part branch to 1 part puppet environment for puppet control repos. This concoction has allowed us to create one-off ephemeral test environments that we all love simply by creating a new git branch.
Since R10k was first introduced we have always used the promotion workflow to usher features into environments. While this workflow served us well there is a different kind of code setup that is now possible with R10k that improves upon what we already know.
Read below to see how r10k can be switched from a promotion based workflow to a trunk based development workflow. But first, some background info.
Promotion workflow
Many environments use the r10k workflow where code is created in feature branches then merged to dev, then merged up to QA then acceptance and finally the coveted PRODUCTION branch. Additionally, there is usually an agreement within the team around which branch is the source of truth, but many times the answer is “it depends”.
This workflow is present at most puppet installations and has proven to reduce bugs, minimize downtime and improve confidence. I refer to this as the promotion workflow. This is a good strategy and has worked well over the years. Although it does have some issues which I will detail below.
A typical scenario:
- merge feature_branch into dev
- merge dev into QA
- merge QA into acceptance (pre-prod)
- merge acceptance into production
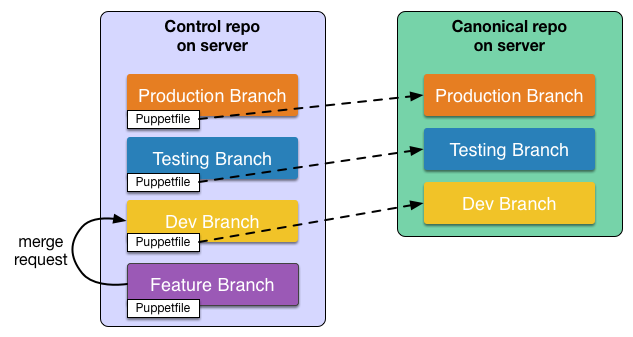
This workflow usually stops bugs at various points as access to different networks and data-centers are mixed in.
Bug Fixes
If there is a code issue anywhere in this cycle, you simply create a new branch and merge that fix into the branch and voila.
A typical bug-fix scenario:
- Create bug-fix branch based off of branch where the fix will be applied (destination)
- Make changes
- Create commit and pull request
- Have team review and merge to destination branch
But what about the other branches / environments? If you want the fix to also be applied to the other environments you will also need to merge that fix to all the other branches. This can be done with a cherry-pick pretty easily. However, cherry picks will create unique commit checksums when applied and sometimes cause code conflicts that have to be resolved. Additionally, you have to do this for EVERY BRANCH!
- Quick and dirty
- Can take a long time to patch other branches
- Code conflicts might occur
- Branches will never be in sync again
- Cherry picked commit will be unique for each branch
Another way to push a bug-fix is to create a bug-fix branch from your development branch. Merge the bug-fix branch into development where all feature branches are merged into. Once merged into development you then merge upwards into QA, Acceptance and finally PRODUCTION! This is the cleanest way to patch a bug in your puppet code. But it has a few issues.
- Takes multiple merge requests
- Can introduce new features or changes into other branches other than the bug fix
- Can take a long time, sometimes weeks based on culture and policies
I would be willing to bet most of you have a a control repo with a messy history of commits, tons of implicit merge commits and branches that are 1000s of commits behind each other. This is unfortunately perfectly normal due to having a puppet environment tightly coupled to a git branch and promoting code to each environment.
There are other strategies that work differently but also have some drawbacks. But ultimately the problem lies mostly with having long lived branches as the article suggests.
Whats the solution?
If we want to simplify our control-repo we simply remove branches. Mo branches, mo problems. No Code is the best code. Yes I am serious here.
But if we remove branches how do we test code? Can we test code in a environment without having to create a branch? YES. Read below.
Introducing YAML based environments
A YAML based environment is one that is created via a manually or dynamically assigned map of a code revision to environment name. In essence, you assign a code revision to an environment of your choice. You can even have 100 puppet environments while only maintaining a single git branch.
Furthermore, for the first time ever you can assign a puppet environment to a git tag and version your control repo like a puppet module without any extra work.
With an implementation of YAML based environments you can fully utilize TRUNK BASED DEVELOPMENT for your puppet codebase.
YAML based environments bring a few extra advantages
- Low number of branches, 1-3 max (not including ephemeral feature branches)
- Create versioned releases from the control repo
- Deploy code/releases to any environment
- No more environment based code promotion
How is this possible?
R10k by default maps the branch name to a environment name with the same name. If you want to manually control this behavior all you need to supply is a map for r10k to use. In the simplest form a YAML file similar to below is all that is needed to manually assign code to an environment. What this file details is the environment name, location of source code and the revision of code to use. R10k will deploy the code based on these parameters like you would expect.
This map file can be updated at any time and would live outside of the control repo. However, just because the map is updated doesn’t mean your code is deployed. You still need to run the code deployment command for r10k/code manager. Furthermore, R10k can even call an http API or any script to produce the same content the below file contains. Obviously, you would wire up a git hook to auto deploy this though. 😁
# /etc/puppetlabs/r10k/environments.yaml
---
production:
type: git
remote: git@github.com/puppetlabs/puppet-control-repo.git
ref: v0.2.0
qa:
type: git
remote: git@github.com/puppetlabs/puppet-control-repo.git
ref: 3cb49372
test:
type: git
remote: git@github.com/puppetlabs/puppet-control-repo.git
ref: 89daf111
development:
type: git
remote: git@github.com/puppetlabs/puppet-control-repo.git
ref: main
Eating cake
Now, some may have noticed that a manually assigned map of code to environments doesn’t allow for the dynamic environment creation we are accustomed to. While this is true, you should know that R10k allows you to have multiple sources. This means you can configure R10k to use YAML and git based (traditional) thus bringing both worlds together into a true TRUNK based development workflow with automatic environment creation.
Below is a snippet of a basic setup for puppet enterprise. Non PE users can use the r10k puppet module with a similar hiera key
# control_repo/data/common.yaml
puppet_enterprise::master::code_manager::sources:
puppet:
remote: 'N/A'
type: yaml
config: '/etc/puppetlabs/r10k/environments.yaml'
git:
# 1/1 environment/branch
remote: 'https://github.com/nwops/kontrol-repo.git'
type: git
prefix: false
# Just in case someone pushes similar branch names, ignore to prevent collision
ignore_branch_prefixes:
- main
- production
- qa
- test
- development
With this setup in place not only do I have a single branch called main, I also have four environments at various code revisions, in addition to a ephemeral environment for a hot-fix release that is mapped to the respective branch name.
I can update my main branch without affecting my environments and can also selectively introduce the hot-fix code to any environment as well without merging code. Once I have proven the hot-fix code works only then will I merge it to main. Because my development environment is fed from the main branch it will start getting that hot-fix.
Because I have assigned code rather than merging I have more flexibility of how, when and where code is deployed. All branches start from main and merge back into main.
Is this all worth yet?
Absolutely, while this setup is slightly different from the traditional setup, the amount of change required is minimal and the payoff is huge IMHO. Simplicity should always be the preferred choice and a single branch couldn’t be any simpler. If you are thinking about implementing a YAML based environment and switching to a true trunk based development workflow please ensure the entire team is on board because this is a change everyone needs to be aware of.
Basic requirements
The only basic requirement I know is R10K 3.13+.
If using PE you need PE 2019.8.9+ or 2021.3+
I ran into a bug with an earlier version of R10k despite the feature existence in 3.9. Might have just been a code manager thing so YMMV.
Additional requirements are the yaml environments map file and configuration of r10k to use the yaml environments. Both of these items are shown above but your implementation will be different.
If something a little more dynamic is warranted you can switch to the exec type and have a script produce the map content instead of feeding R10k a static file.
Caveats and gotchas
When setting this up initially there is a chicken/egg issue where code manager / r10k config files need to be updated first. So if your r10k config is in puppet code a puppet run would need to go first to setup the additional R10k source. I also recommend you start with a non production branch in your environment.yaml source. Should you need to reconfigure your hiera data you may run into that chicken/egg problem. I also recommend starting with the basic YAML file for testing purposes and then switch to the exec type if your code changes often.
You may run into issues where the user running r10k may not have permission to read the YAML file or execute the script. Please ensure the correct permissions are set. For PE, this means the pe-puppet user must have read/write permissions on the yaml or script file.
If you want to maintain your long lived branches you can throw those branch names in the r10k ignore_branch_prefixes setting and then recreate in the map file. This is a short term solution but a good way to bridge the gap because you now have complete control over which code goes into the acceptance environment.
# /etc/puppetlabs/r10k/environments.yaml
acceptance:
type: git
remote: git@github.com/puppetlabs/puppet-control-repo.git
ref: acceptance
# control_repo/data/common.yaml
git:
# 1/1 environment/branch
remote: 'https://github.com/nwops/kontrol-repo.git'
type: git
prefix: false
# Just in case someone pushes similar branch names, ignore to prevent collision
ignore_branch_prefixes:
- main
- acceptance
Getting help
At the moment there are only a few organizations that have this implemented. While there isn’t much to changing R10k over to using a YAML based config, a half day of work for me at least. You can reach out on the puppet community slack for assistance or hire us for this task. We are a Puppet Service Delivery Partner and can help with this specific setup and much more. You can reach us at
automation@nwops.io or @nwops on the puppet community slack.
This change isn’t just about checking a box, it is about moving your team to a more efficient workflow.